

Das Parallelkorpus German/Spanisch (German/Spanish Parallel Corpus) PaGeS, ist Teil von PaCorEs (Parallel Corpora Spanish) — einem laufenden Großprojekt, das eine Reihe von zweisprachigen Parallelkorpora mit Spanisch als zentraler Sprache sammeln soll. Bisher umfasst das Projekt drei weitere Korpora, die sich in unterschiedlichen Stadien der Fertigstellung befinden und online frei verfügbar sind: Corpus PaEnS (Englisch<>Spanisch), Corpus PaCheS (Chinesisch<>Spanisch) und Corpus PaFreS (Französisch<>Spanisch).
Das Parallel Corpus German / Spanish, PaGeS , ist ein bilinguales Parallelkorpus, das aus zwei Hauptteilen besteht: dem Kernkorpus und den Ergänzungen.
Das Kernkorpus enthält Originaltexte in Deutsch und Spanisch und deren veröffentlichte Übersetzungen. Es umfasst eine Sammlung von 229 Werken, überwiegend Belletristik (ca. 89 %) sowie Sachtexte verschiedener Gattungen (Essays, Ratgeberliteratur, biographische und populärwissenschaftliche Texte). Die enthaltenen Werke wurden nicht vollständig sondern in Auszügen aufgenommen, um eine größere Vielfalt an Texten zu erzielen.
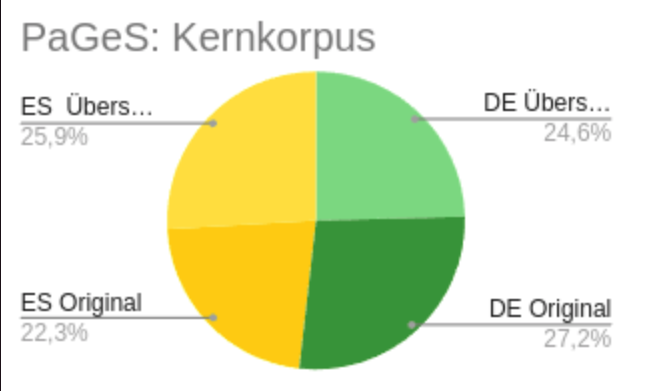
Das Kernkorpus von PaGeS (s. die Grafik unten) enthält ca. 42.000.000 Tokens und 1.246.733 Bisegmente,, d.h. Paare von alignierten Textchunks (Sätze oder kleinere Segmente).
Um die Qualität zu sichern, wurden die Texte auf verschiedenen Ebenen manuell revidiert und die automatische Alignierung der Bisegmente vom LF-Aligner, eventuell mit YouAlign oder Gargantua erfolgte, wurde manuell vollständig geprüft. Lemmatisierung und PoS-Tagging der deutschen Texte wurde auf Basis des Stuttgart-Tübingen-Tagsets (STTS) mit Treetagger durchgeführt, während die spanischen Texte mit Freeling bearbeitet wurden. Die Tags beider Texte wurden anschließend den Universal POS-Tags zugeordnet, die die wichtigsten Wortartenkategorien markieren.
Für jeden Beleg wird die Originalquelle angegeben, die Informationen zu Autor, Titel, Erscheinungsjahr der ersten und der verwendeten Ausgabe enthält, sowie den Teil oder das Kapitel des Werks anzeigt, aus dem der Beleg stammt. Die vollständigen bibliographischen Angaben der Werke vom PaGeS sind hier zu finden.
Das Teilkorpus der Ergänzungen enthält insgesamt über 80 Millionen Textwörter. Die Ergänzungen beinhalten bisher:
In naher Zukunft werden voraussichtlich neue Sammlungen zweisprachiger Texte unterschiedlicher Herkunft hinzugefügt.
Auch wenn der ursprüngliche Anstoß zur Erstellung von PaGeS aus dem Bereich der kontrastiven linguistischen Forschung kam, hat uns die sehr gute Aufnahme bei ganz unterschiedlichen Nutzern dazu veranlasst, Anstrengungen in Bezug auf die Benutzerfreundlichkeit und Standardisierung zu unternehmen, um das Korpus zu einer multifunktionalen Ressource zu machen, die den Anforderungen sehr unterschiedlicher Nutzergruppen gerecht wird.
Unser Ziel ist es, eine verlässliche Sprachressource für Deutsch und Spanisch zu schaffen, die für viele Zwecke geeignet ist. Dazu gehören allgemeine Untersuchungen in den Bereichen der kontrastiven Linguistik, der linguistischen Typologie, der Übersetzungswissenschaft und der bilingualen Lexikographie sowie die Nutzung als Datenquelle für maschinelle Übersetzungssysteme.
PaGeS hat sich auch als ein sehr nützliches und weit verbreitetes Tool für ÜbersetzerInnen und Deutsch- oder Spanischlernende auf mittlerem bis fortgeschrittenem Niveau erwiesen, um eine Vielzahl von Übersetzungsvorschlägen zu erhalten, die von Menschen gemacht wurden und in Anwendungsbeispielen aufgezeigt werden.
Ausführliche Informationen zu PaGeS finden Sie auf der Seite Publikationen. Siehe auch Doval, Irene / Sánchez Nieto, M.ª Teresa (en prensa): Parallel Corpora Spanish (PaCorES): A collection of multifunctional parallel corpora. In: RESLA. Revista Española de Lingüística Aplicada / Spanish Journal of Applied Linguistics.
Trotz unserer Bemühungen haben sich sicherlich einige Fehler eingeschlichen. Wenn Sie sie finden, lassen Sie es uns bitte wissen, indem Sie hier clicken.
Hinweis:
Wenn Sie PaGeS in Ihrer Arbeit verwenden, geben Sie es bitte als Quelle an und benachrichtigen Sie uns: corpuspages@usc.es. Damit unterstützen Sie den Fortbestand des Projekts.
Statistiken PaGeS
Kernkorpus
| SPRACHE | CHARACTERS | TEXTWÖRTER | TOKENS | MSTTRATIO* | BISEGMENTE | WERKE |
| Deutsch Original | 48.949.765 | 9.419.402 | 11.049.990 | 0.577 | 702.731 | 114 |
| Spanisch Übersetzung | 46.634.694 | 10.083.202 | 11.581.354 | 0.542 | ||
| Spanisch Original | 40.047.261 | 8.579.478 | 9.809.708 | 0,539 | 544.002 | 115 |
| Deutsch Übersetzung | 44.210.720 | 8.494.546 | 9.924.406 | 0.572 | ||
| Gesamt | 179.842.440 | 36.576.628 | 42.365.458 | 0.557 | 1.246.733 | 229 |
Ergänzungen 1: Belletristik, Übersetzungen aus einer dritten Sprache
| SPRACHE | ZEICHEN | TEXTWÖRTER | TOKENS | MSTTRATIO* | BISEGMENTE | WERKE |
| Deutsch Übersetzung | 10.885.529 | 2.097.569 | 2.463.109 | 0.569 | 152.077 | 18 |
| Spanisch Übersetzung | 10.008.379 | 2.148.750 | 2.479.765 | 0.545 | ||
| Gesamt | 20.893.908 | 4.942.874 | 4.246.319 | 0.557 | 152.077 | 18 |
Ergänzungen 2: Europarl v7
| SPRACHE | ZEICHEN | TEXTWÖRTER | TOKENS | MSTTRATIO* | BISEGMENTE |
| Deutsch | 203.075.349 | 33.405.712 | 37.703.328 | 0.542 | 1.555.009 |
| Spanisch | 190.849.843 | 37.694.928 | 41.518.229 | 0.481 | |
| Gesamt | 393.925.192 | 71.100.640 | 79.221.557 | 0.512 | 1.555.009 |
Ergänzungen 3: TED-Talks
| SPRACHE | ZEICHEN | TEXTWÖRTER | TOKENS | MSTTRATIO* | BISEGMENTE |
| Deutsch | 23.827.783 | 5.046.593 | 5.805.812 | 0.506 | 321.924 |
| Spanisch | 25.347.694 | 4.754.108 | 5.599.587 | 0.543 | |
| Gesamt | 49.169.470 | 9.800.701 | 11.405.399 | 0.525 | 321.924 |
Ergänzungen 4: OpenSubtitles v2018
| SPRACHE | ZEICHEN | TEXTWÖRTER | TOKENS | MSTTRATIO* | BISEGMENTE |
| Deutsch | 175.689.253 | 37.703.271 | 47.050.044 | 0,565 | 5.840.417 |
| Spanisch | 159.707.973 | 36.664.180 | 46.709.094 | 0,575 | |
| Gesamt | 335.397.226 | 74.367.451 | 93.759.138 | 0.570 | 5.840.417 |
Ergänzungen 5: MSD Manuals
| SPRACHE | ZEICHEN | TEXTWÖRTER | TOKENS | MSTTRATIO* | BISEGMENTE |
| Deutsch | 53.822.200 | 7.912.799 | 8.955.905 | 0,5349 | 583.774 |
| Spanisch | 52.516.887 | 9.593.480 | 10.539.033 | 0,4573 | |
| Gesamt | 106.339.087 | 17.506.279 | 19.494.938 | 0.496 | 583.774 |
*MSTTR steht für Mean Segmental Type-Token Ratio (MSTTR), d. h. das durchschnittliche TTR für jeweils 1000 Token.
(Stand: 07/01/2026, Release 2.3)




