

El Corpus paralelo alemán / español, PaGeS, es un corpus bilingüe compuesto de dos partes diferenciadas: un corpus nuclear y unos suplementos.
El corpus nuclear está formado por textos originales en alemán y español y sus respectivas traducciones. Consiste en una colección de 178 obras de ficción (en torno al 80% de novelas y relatos breves) y no ficción (ensayos y textos científicos divulgativos). Las obras seleccionadas están representadas no por los textos completos sino por muestras, lo que permite una mejor sección transversal de los textos.
Esta parte de PaGeS (vid. infra) contiene cerca de 38.000.000 tokens y 1.117.040 bisegmentos, es decir, pares de unidades alineadas (oraciones o unidades suboracionales).
Para garantizar la calidad se han verificado manualmente los textos incluidos a diferentes niveles y se ha revisado íntegramente el alineado automático de los bisegmentos, ejecutado con LF-Aligner, algunos con YouAlign o Gargantua. Los textos alemanes se han lematizado y etiquetado con Treetagger y los españoles con Freeling. Las etiquetas de ambos han sido posteriormente correlacionadas con las etiquetas universales, que marcan las principales categorías de parte de discurso.
De cada ocurrencia se facilita la fuente original que incluye información sobre el autor, título, año de la primera publicación, en su caso, de la edición utilizada y la parte o capítulo dentro de la obra a la que pertenece la ocurrencia. Las indicaciones bibliográficas completas de las obras incluidas en PaGeS figuran aquí.
Los suplementos comprenden un total de unos 80 millones de palabras. Por el momento incluyen:
En un futuro próximo se prevé incorporar nuevas colecciones de textos bilingües de origen diverso.
Aunque el impulso inicial para la creación de PaGeS fue la investigación lingüística contrastiva, la muy buena acogida por parte de usuarios muy diversos nos ha motivado a esforzarnos en conseguir una mayor interoperabilidad y estandarización, a fin de convertir a PaGeS en un recurso multifuncional capaz de satisfacer las necesidades bien diferenciadas de nuestros usuarios.
Nuestro objetivo es construir un recurso lingüístico representativo para el alemán y el español que pueda ser explotado para múltiples propósitos. Aquí se incluye la investigación general en lingüística contrastiva, tipología lingüística, estudios de traducción y lexicografía bilingüe o el suministro de datos de entrenamiento a sistemas de traducción automática. PaGeS es además un recurso muy útil y ampliamente usado por parte de traductores y estudiantes de alemán o español como lengua extranjera de niveles intermedios y avanzados para obtener una multitud de sugerencias de traducción, realizadas por humanos y mostradas en ejemplos de uso.
Para una información más detallada acerca de PaGeS puede consultarse la página de publicaciones.
A pesar de todos los esfuerzos, estamos seguros de que se han deslizado errores. Por ello, le agradecemos que si los detecta nos lo comunique haciendo click aquí.
Nota
Si usa PaGeS en tus trabajos, por favor indíquelo y comuníquenoslo a: corpuspages@usc.es. Así contribuye a la sostenibilidad del proyecto.
Estadísticas PaGeS
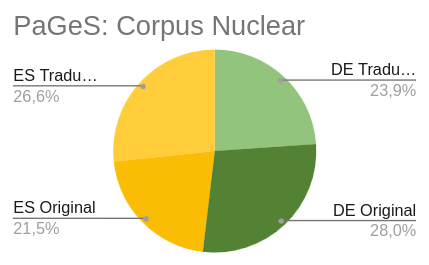
Corpus nuclear
| LENGUA | CARACTERES | TOKENS | PALABRAS | MSTTRATIO* | BISEGMENTOS | OBRAS |
| Alemán Original | 45.774.970 | 10.313.588 | 8.784.334 | 0.577 | 662.307 | 108 |
| Español Traducción | 43.606.674 | 10.829.682 | 9.415.876 | 0.542 | ||
| Español Original | 35.148.172 | 8.687.999 | 7.598.269 | 0.539 | 484.590 | 91 |
| Alemán Traducción | 39.138.385 | 8.787.719 | 7.517.057 | 0.572 | ||
| Total | 163.668.201 | 38.618.725 | 33.315.536 | 0.5575 | 1.146.897 | 199 |
Suplementos 1: Obras de ficción traducidas
| LENGUA | CARACTERES | TOKENS | PALABRAS | MSTTRATIO* | BISEGMENTOS | OBRAS |
| Alemán Traducción | 10.885.529 | 2.463.109 | 2.097.569 | 0.569 | 152.077 | 18 |
| Español Traducción | 10.008.379 | 2.479.765 | 2.148.750 | 0.545 | ||
| Total | 20.893.908 | 4.942.874 | 4.246.319 | 0.557 | 152.077 | 18 |
Suplementos 2: Europarl v7
| LENGUA | CARACTERES | TOKENS | PALABRAS | MSTTRATIO* | BISEGMENTOS |
| Alemán | 203.075.349 | 37.703.328 | 33.405.712 | 0.542 | 1.555.845 |
| Español | 190.849.843 | 41.518.229 | 37.694.928 | 0.481 | |
| Total | 393.925.192 | 79.221.557 | 71.100.640 | 0.5115 | 1.555.845 |
Suplementos 3: TED-Talks
| LENGUA | CARACTERES | TOKENS | PALABRAS | MSTTRATIO* | BISEGMENTOS |
| Alemán | 25.344.941 | 5.599.587 | 4.754.108 | 0.542 | 321.924 |
| Español | 23.824.529 | 5.805.812 | 5.046.593 | 0.506 | |
| Total | 49.169.470 | 11.405.399 | 9.800.701 | 0.525 | 321.924 |
*MSTTR (Mean Segmental Type-Token Ratio) es la media de TTR por cada 1000 tokens.
(Edición: 01/12/2023, Release 2.1)




