

O Corpus Paralelo alemán / español, (German/Spanish Parallel Corpus), PaGeS, forma parte dun proxecto maior en curso, PaCorEs (Parallel Corpora Spanish), cuxo obxetivo é recopilar unha serie de corpus paralelos bilingües co español como lingua central. Ata o de agora, o proxecto inclúe outros tres corpus que se atopan en diferentes fases de desenrrolo, dispoñibles libremente en liña: Corpus PaEnS (inglés<>español), Corpus PaCheS (chino<>español) e Corpus PaFreS (francés<>español).
O Corpus Paralelo alemán / español, PaGeS, é un corpus bilingüe composto de dús partes diferenciadas: un corpus nuclear e uns suplementos.
O corpus nuclear está formado por textos orixinais en alemán e español e as súas respetivas traducións. Consiste nuha colección de 229 obras de ficción (en torno ao 89% de novelas e relatos breves) e non ficción (ensaios e textos científicos divulgativos). As obras seleccionadas están representadas non polos textos completos senón por mostras, o que permite unha mellor sección transversal dos textos.
Esta parte de PaGeS (vid. infra) contén cerca de 42.000.000 tokens e 1.246.733 bisegmentos, é dicir, pares de unidades aliñaadas (oracións ou unidades suboracionales).
Para garantir a calidade verificaronse manualmente os textos incluidos a diferentes niveis e revisáronse íntegramente o alineado automático dos bisegmentos, executado con LF-Aligner, algúns con YouAlign ou Gargantua. Os textos alemans lematizaronse e etiquetáronse con Treetagger e os españoles con Freeling. As etiquetas de ambos foron posteriormente correlacionadas cas etiquetas universales, que marcan as principais categorías de parte de discurso.
De cada ocurrencia facilitouse a fonte orixinal que inclúe información sobre o autor, título, año da primeira publicación, no seu caso, da edición empregada e a parte o capítulo dentro da obra á que pertence a ocurrencia. As indicacións bibliográficas completas das obras incluidas en PaGeS figuran aquí.
Os suplementos comprenden un total dun 80 millóns de palabras. Polo momento inclún:
Nun futuro próximo prevése incorporar novas coleccións de textos bilingües de orixe diverso.
Aínda que o impulso inicial para a creación de PaGeS foi a investigación lingüística contrastiva, a moi boa acollida por parte de usuarios moi diversos motivounos de cara a esforzarnos en conseguir unha maior interoperabilidade e estandarización, a fin de convertir a PaGeS nun recurso multifuncional capaz de satisfacer as necesidades ben diferenciadas de nosos usuarios.
Noso obxetivo é construir un recurso lingüístico representativo para o alemán e o español que poida ser explotado para múltiples propósitos. Aquí inclúese a investigación xeral en lingüística contrastiva, tipoloxía lingüística, estudos de tradución e lexicografía bilingüe ou o suministro de datos de entrenamento a sistemas de tradución automática. PaGeS é ademáis un recurso moi útil e ampliamente empregado por parte de traductores e estudantes de alemán ou español como lingua extranxeira de niveis intermedios e avanzados para obter unha multitude de suxerencias de tradución, realizadas por humanos e mostradas en exemplos de uso.
Para unha información máis detallada acerca de PaGeS pódese consultar a páxina de publicacións. Véxase especialmente Doval, Irene / Sánchez Nieto, M.ª Teresa (en prensa): Parallel Corpora Spanish (PaCorES): A collection of multifunctional parallel corpora. In: RESLA. Revista Española de Lingüística Aplicada / Spanish Journal of Applied Linguistics.
A pesar de tóodolos esforzos, estamos seguros de que se deslizaron erros. Por iso, agradec&eacte;moslle que si os detecta nolo comunique facendo click aquí.
Nota
Se empregas PaGeS nos teus traballos, por favor indícao e comunícanolo a: corpuspages@usc.es. Así contribúes á sostenibilidade do proxecto.
Estatísticas PaGeS
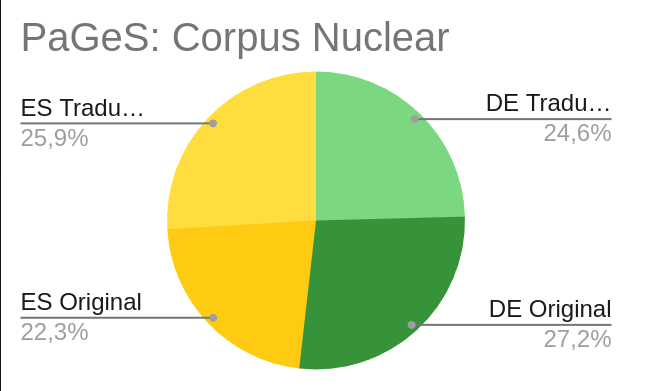
Corpus nuclear
| LINGUA | CARACTERES | PALABRAS | TOKENS | MSTTRATIO* | BISEGMENTOS | OBRAS |
| Alemán Orixinal | 48.949.765 | 9.419.402 | 11.049.990 | 0.577 | 702.731 | 114 |
| Español Tradución | 46.634.694 | 10.083.202 | 11.581.354 | 0.542 | ||
| Español Orixinal | 40.047.261 | 8.579.478 | 9.809.708 | 0,539 | 544.002 | 115 |
| Alemán Tradución | 44.210.720 | 8.494.546 | 9.924.406 | 0.572 | ||
| Total | 179.842.440 | 36.576.628 | 42.365.458 | 0.557 | 1.246.733 | 229 |
Suplementos 1: Obras de ficción traducidas
| LINGUA | CARACTERES | PALABRAS | TOKENS | MSTTRATIO* | BISEGMENTOS | OBRAS |
| Alemán Tradución | 10.885.529 | 2.097.569 | 2.463.109 | 0.569 | 152.077 | 18 |
| Español Tradución | 10.008.379 | 2.148.750 | 2.479.765 | 0.545 | ||
| Total | 20.893.908 | 4.246.319 | 4.942.874 | 0.557 | 152.077 | 18 |
Suplementos 2: Europarl v7
| LINGUA | CARACTERES | PALABRAS | TOKENS | MSTTRATIO* | BISEGMENTOS |
| Alemán | 203.075.349 | 33.405.712 | 37.703.328 | 0.542 | 1.555.009 |
| Español | 190.849.843 | 37.694.928 | 41.518.229 | 0.481 | |
| Total | 393.925.192 | 71.100.640 | 79.221.557 | 0.512 | 1.555.009 |
Suplementos 3: TED-Talks
| LINGUA | CARACTERES | PALABRAS | TOKENS | MSTTRATIO* | BISEGMENTOS |
| Alemán | 23.827.783 | 5.805.812 | 5.805.812 | 0.506 | 321.924 |
| Español | 25.347.694 | 4.754.108 | 5.599.587 | 0.543 | |
| Total | 49.175.477 | 9.800.701 | 11.405.399 | 0.525 | 321.924 |
Suplementos 4: OpenSubtitles v2018
| LINGUA | CARACTERES | PALABRAS | TOKENS | MSTTRATIO* | BISEGMENTOS |
| Alemán | 175.689.253 | 37.703.271 | 47.050.044 | 0,565 | 5.840.417 |
| Español | 159.707.973 | 36.664.180 | 46.709.094 | 0,575 | |
| Total | 335.397.226 | 74.367.451 | 93.759.138 | 0.570 | 5.840.417 |
Suplementos 5: MSD Manuals´
| LINGUA | CARACTERES | PALABRAS | TOKENS | MSTTRATIO* | BISEGMENTOS |
| Alemán | 53.822.200 | 7.912.799 | 8.955.905 | 0,5349 | 583.774 |
| Español | 52.516.887 | 9.593.480 | 10.539.033 | 0,4573 | |
| Total | 106.339.087 | 17.506.279 | 19.494.938 | 0.496 | 583.774 |
*MSTTR (Mean Segmental Type-Token Ratio) é a media de TTR por cada 1000 tokens.
(Edición: 07/01/2026, Release 2.3)




