

The German/Spanish Parallel Corpus, PaGeS, is part of an ongoing major project PaCorEs, Parallel Corpora Spanish, which aims to collect a series of bilingual parallel corpora with Spanish as the central language. So far, the project includes three other corpora at different stages of completion, all of them freely available online: Corpus PaEnS English <> Spanish, Corpus PaCheS Chinese <> Spanish and Corpus PaFreS French <> Spanish.
The PaGeS Corpus is a bilingual parallel corpus composed of two major parts: the core corpus and the supplements.
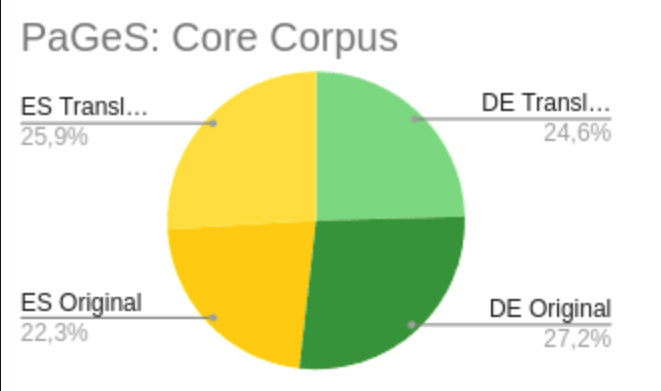
The core corpus is comprised of original texts in German and Spanish and their respective translations. It includes 229 works of fiction —novels and short stories, making up around 89% — as well as non-fiction — essays and popular science texts. The selected works are represented not by the full texts, but rather by samples, allowing for a better cross-section of the texts.
This part of PaGeS (s. below) contains nearly 42,000,000 tokens and 1.246.733 bisegments, i.e. pairs of aligned text chunks (sentences or subsentential units/segments).
To guarantee overall quality, the texts have been manually verified at different levels and the automatic alignment of the bisegments, performed by LF-Aligner, some of them by YouAlign or Gargantua has been manually reviewed. The German texts have been lemmatized and pos-tagged with Treetagger and the Spanish texts with Freeling. The tags of both have been subsequently mapped to the Universal POS tags, that mark the core part-of-speech categories.
For each occurrence, the original source is provided, which includes information on the author, title, year of the first publication, and — if applicable —the edition used and the part or chapter within the work to which the specific occurrence belongs. The complete bibliographic data of the works included in PaGeS can be found here.
The supplements contain a total of more than 80 million words. The supplements include so far:
In the near future, new collections of bilingual texts of diverse origin are expected to be added.
Even though the initial impulse for the creation of PaGeS was to provide a broad source of data for contrastive linguistic research, the excellent reception by very diverse users has motivated us to strive for greater interoperability and standardization in order to make PaGeS a multifunctional resource able to meet the differentiated needs of our users. We aim at building a representative language resource for the language pair German / Spanish that can be exploited for multiple purposes such as general research in contrastive linguistics, linguistic typology, translation studies and bilingual lexicography, as well as the supply of training data to machine translation systems. PaGeS has also proven to be a very useful and widely used resource by translators and learners of German or Spanish as Foreign Languages at intermediate and advanced levels to obtain a multitude of translation suggestions made by humans and presented within examples of real language use.
For more detailed information about PaGeS, see the publications webpage and Doval, Irene / Sánchez Nieto, M.ª Teresa (en prensa): Parallel Corpora Spanish (PaCorES): A collection of multifunctional parallel corpora. In: RESLA. Revista Española de Lingüística Aplicada / Spanish Journal of Applied Linguistics.
Despite our best efforts, some mistakes have undoubtedly slipped through. If you come across any, please let us know by clicking here.
Notice:
If you use PaGeS in your work, please indicate it and let us know: corpuspages@usc.es. This way you contribute to the sustainability of the project.
Statistics PaGeS
Core Corpus
| LANGUAGE | CHARACTERS | WORDS | TOKENS | MSTTRATIO* | BISEGMENTS | WORKS |
| German Original | 48.949.765 | 9.419.402 | 11.049.990 | 0.577 | 702.731 | 114 |
| Spanish Translation | 46.634.694 | 10.083.202 | 11.581.354 | 0.542 | ||
| Spanish Original | 40.047.261 | 8.579.478 | 9.809.708 | 0,539 | 544.002 | 115 |
| German Translation | 44.210.720 | 8.494.546 | 9.924.406 | 0.572 | ||
| Total | 179.842.440 | 36.576.628 | 42.365.458 | 0.557 | 1.246.733 | 229 |
Supplements 1: Fiction translated from a third language
| LANGUAGE | CHARACTERS | WORDS | TOKENS | MSTTRATIO* | BISEGMENTS | WORKS |
| German Translation | 10.885.529 | 2.097.569 | 2.463.109 | 0.569 | 152.077 | 18 |
| Spanish Translation | 10.008.379 | 2.148.750 | 2.479.765 | 0.545 | ||
| Total | 20.893.908 | 4.246.319 | 4.942.874 | 0.557 | 152.077 | 18 |
Supplements 2: Europarl v7
| LANGUAGE | CHARACTERS | WORDS | TOKENS | MSTTRATIO* | BISEGMENTS |
| German | 203.075.349 | 33.405.712 | 37.703.328 | 0.542 | 1.555.009 |
| Spanish | 190.849.843 | 37.694.928 | 41.518.229 | 0.481 | |
| Total | 393.925.192 | 71.100.640 | 79.221.557 | 0.5115 | 1.555.009 |
Supplements 3: TED-Talks
| LANGUAGE | CHARACTERS | WORDS | TOKENS | MSTTRATIO* | BISEGMENTS |
| German | 23.827.783 | 5.046.593 | 5.805.812 | 0.506 | 321.924 |
| Spanish | 25.347.694 | 4.754.108 | 5.599.587 | 0,543 | |
| Total | 49.175.477 | 9.800.701 | 11.405.399 | 0.525 | 321.924 |
Supplements 4: OpenSubtitles v2018
| LANGUAGE | CHARACTERS | WORDS | TOKENS | MSTTRATIO* | BISEGMENTS |
| German | 175.689.253 | 37.703.271 | 47.050.044 | 0,565 | 5.840.417 |
| Spanish | 159.707.973 | 36.664.180 | 46.709.094 | 0,575 | |
| Total | 335.397.226 | 74.367.451 | 93.759.138 | 0.570 | 5.840.417 |
Supplements 5: MSD Manuals
| LANGUAGE | CHARACTERS | WORDS | TOKENS | MSTTRATIO* | BISEGMENTS |
| German | 53.822.200 | 7.912.799 | 8.955.905 | 0,5349 | 583.774 |
| Spanish | 52.516.887 | 9.593.480 | 10.539.033 | 0,4573 | |
| Total | 106.339.087 | 17.506.279 | 19.494.938 | 0.496 | 583.774 |
*MSTTR is the average TTR (Type/Token Ratio) for each non-overlapping segment of equal size (in this case 1000 tokens).
(Stand: 07/01/2026, Release 2.3)




